Here we will show how to use our Rotating Proxy with Scrapebox. Our Rotating Proxy service includes Rotating Premium Proxy service (stable premium proxies) and Rotating Open Proxy service (unstable public proxies).
1. Use Rotating Proxy in Scrapebox
For Google, we recommend our Rotating Open Proxy. Since Rotating Premium Proxy has limited IPs, Google blocks most of them. Rotating Open Proxy has new IPs every day. It still works for Google searches.
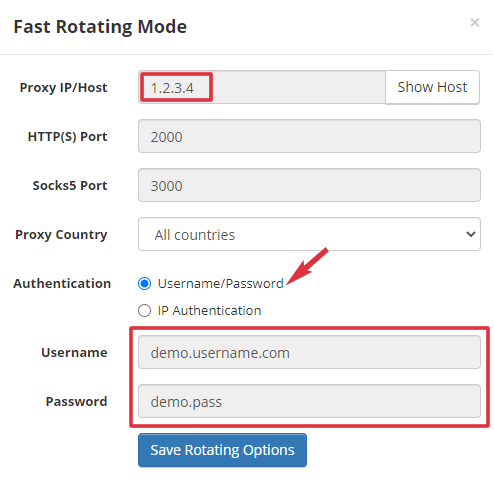
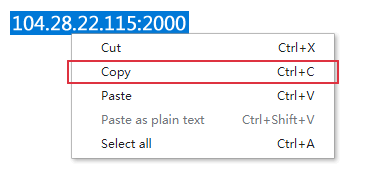
First, copy the IP:Port:Username:Password to the clipboard. Note: 104.28.22.115:2000 and its username/password in this image is just a demo. You should use the real one in your account.
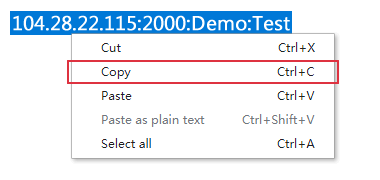
If you use IP authentication, you can just copy the IP:Port. It doesn’t need the username/password.
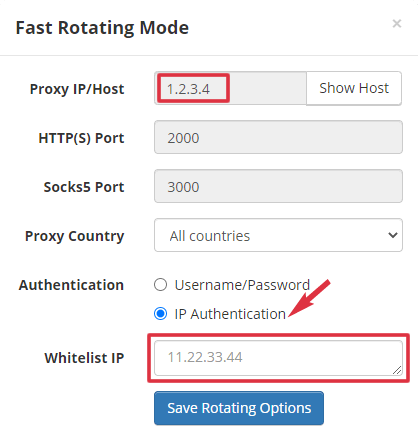
Note: 104.28.22.115:2000 is just a demo. You should see the real one in your client area and whitelist your IP there.
Now you can paste the rotating proxy to Scrapebox by right-clicking the proxy area.
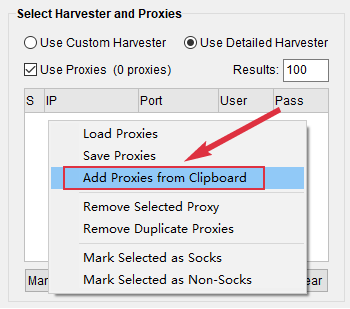
Now the rotating proxy is ready for Scrapebox’s tasks.
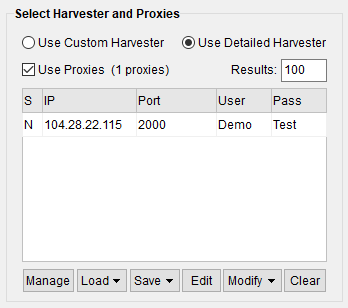
You may ask if all the traffic is from the same IP. No. Every time Scrapebox uses the rotating proxy, it will use a new IP (from the Proxy Pool) to scrape the target website.

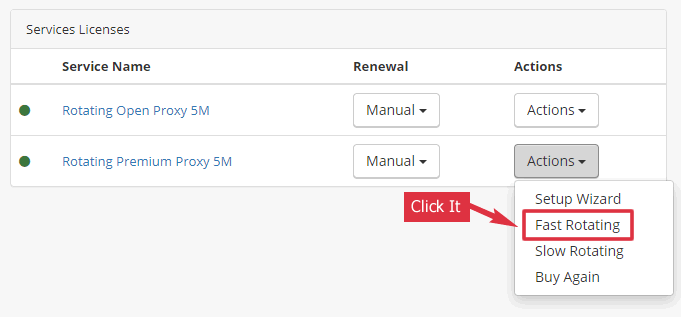
2. Scrapebox Proxy Checker
There is a problem with the proxy checker of Scrapebox. The rotating proxy doesn’t pass its Google test.
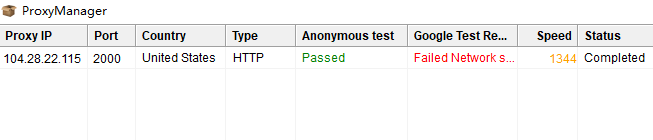
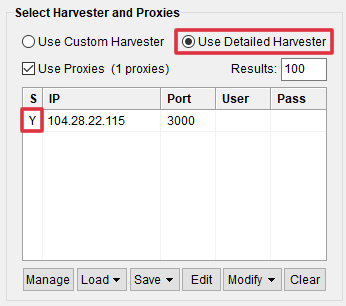
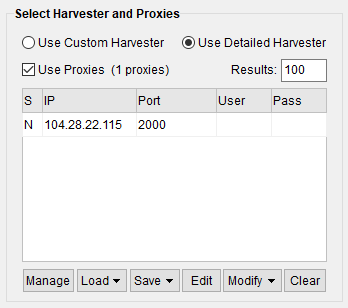
However, you can still use the rotating proxy to get the search results from Google using the “Detailed Harvester”. Note: The “Custom Harvester” failed to do its task using our rotating proxy.

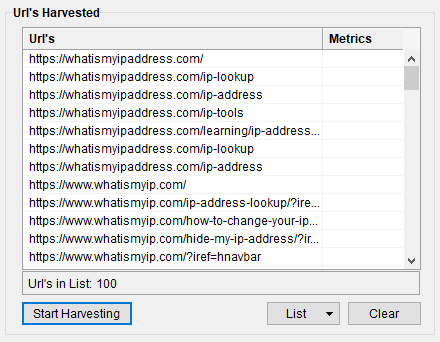
Note: If your country blocks Google, you can use the socks port 3000 of the rotating proxy in Scrapebox. Remember to “Mark it as Socks” in Scrapebox’s proxy section (see Point 2 above).